 Nova服务详解
Nova服务详解
# Nova服务详解
Nova是最后讲解的组件,是因为它所依赖的其他服务,像存储、网络、镜像等都在前面已经详细讲解过了,启动一个虚拟机所需要的资源也都已经准备好了,然后我们再来详细看OpenStack中对虚拟机进行管理的组件Nova。
Nova是用来对虚拟机进行全生命周期的管理,包括虚拟机的创建、维护、销毁等等,Nova也是OpenStack项目中最早的核心项目。在之前的项目中也提到,像Cinder、Neutron、Placement服务都是从早期的Nova服务中独立出去的。当这些功能都独立出去以后,Nova就变成了一个更加专注的项目,专注于统一的计算资源抽象和管理。资源可以是虚拟机、物理机。物理机的管理现在抽取出来归属于独立的Ironic项目,因此Nova现在只专注于虚拟机的管理。
# Nova体系架构
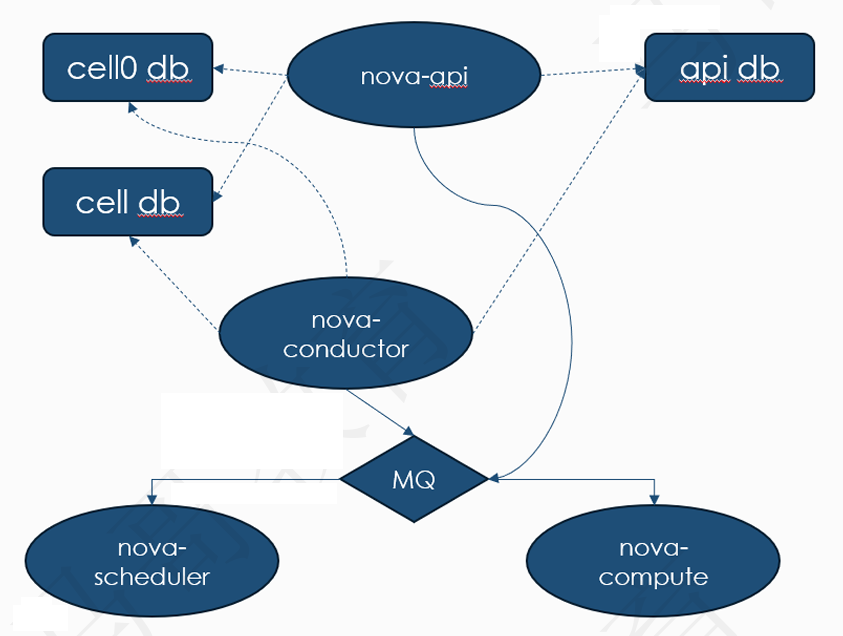
Nova是由多个不同的组件组成,外部通过API接口和它进行交互,nova内部则通过RPC接口进行通信,同时还需要外部数据库来存储虚拟机的相关信息。它的基本体系架构如下图所示:

从图上可以看到,目前Nova的主要组件有API、Conductor、Scheduler、Compute,前三个是部署在控制节点上,最后一个Compute组件主要是部署在计算节点上。
# Nova和Ceph的对接
nova组件也可以和Ceph集群对接,直接使用Ceph的存储池来存放虚拟机的系统盘,可以保证在计算节点故障的时候,能够快速在其他计算节点中重建虚拟机,这也是为什么云存储在OpenStack上最终占据主导地位的原因。
nova和Ceph对接的配置
先在计算节点上安装好ceph-common工具,因为nova需要利用这个工具里提供的命令来挂载ceph 存储到虚拟机上,安装命令是:
yum install ceph-common
然后在Ceph节点上获取cinder keyring文件的一个临时副本:
ceph auth get-key client.cinder | ssh {your-compute-node} tee client.cinder.key
这个命令会把这个副本密钥文件client.cinder.key发送到计算节点上。然后在计算节点上生成一个uuid,命令是:
uuidgen
生成的uuid如下所示:
f1ce6a51-d46b-4af0-88d2-593d45edd899
然后在计算节点上编译一个secret.yml文件,内容如下:
<secret ephemeral='no' private='no'>
<uuid>f1ce6a51-d46b-4af0-88d2-593d45edd899</uuid>
<usage type='ceph'>
<name>client.cinder secret</name>
</usage>
</secret>
2
3
4
5
6
然后定义一个secret,命令是:
sudo virsh secret-define --file secret.xml
它会提示创建成功了一个secret,并生成了一个secret uuid。
Secret f1ce6a51-d46b-4af0-88d2-593d45edd899 created
然后我们将它设置为一个固定的键值对:
sudo virsh secret-set-value --secret f1ce6a51-d46b-4af0-88d2-593d45edd899 \
--base64 $(cat client.cinder.key) && rm client.cinder.key secret.xml
2
设置成功后删除临时的keyring文件和secret.xml文件,这里的操作实际上就是把uuid和认证文件的key绑定到一起。
你在实际测试过程中的uuid值可能不一样,替换为你自己的uuid值即可。
修改/etc/nova/nova.conf文件,添加下面的配置:
[libvirt]
images_rbd_pool=vms
images_type=rbd
images_rbd_ceph_conf=/etc/ceph/ceph.conf
rbd_user = cinder
rbd_secret_uuid = f1ce6a51-d46b-4af0-88d2-593d45edd899
2
3
4
5
6
修改完成后,重启nova服务,命令是:
systemctl restart openstack-nova-compute
重启完成后,新建的虚拟机默认系统盘就会在Ceph集群上了,可以创建一个虚拟机测试一下。
# Cells V2
Cell这个概念实际上也是用来隔离资源的一个抽象逻辑概念,目的是为了在计算节点数据太多时,为了避免单个数据库和消息队列的压力过大,通过cell把计算节点分隔到不同的组里,每个组对接单独的数据库和消息队列,以降低单个数据库和消息队列的压力,提高整个OpenStack集群的稳定性和各个组件的响应速度。
我们之前部署的一主一从架构就是单个cell架构,单个cell的架构图如下所示:
多cell架构图如下所示

和单cell架构相比,从图中我们可以看到,多cell架构使用cell的概念把不同的计算节点隔离开来,每个独立的cell中都有独立的:
- nova-conductor,负责和db以及上层的super-conductor交互
- Cell Database,负责存储单个Cell中所有计算节点的信息
- Cell MQ,负责处理单个Cell内组件的消息队列并和上级的nova-api、super-condutor交互,传递控制消息。 super conductor负责调度所有的Cell中的nova-conductor。
# nova虚拟机管理
常见的虚拟机管理操作有以下这些:
# 冷迁移、规格调整和热迁移
迁移指的是把虚拟机从一台计算节点转移到另外一个计算节点的操作,分为冷迁移和热迁移两种方式,冷迁移比较好理解,就是迁移的过程中虚拟机处于关机或者挂起的状态,而热迁移则是迁移过程虚拟机一直处于可用状态。不管是冷迁移还是热迁移,都会受到一些条件的制约,常见的有:
- 迁移前后的计算节点硬件规格是否一样,计算节点硬件不同时,支持的硬件特性也不一样,特别是CPU的兼容性,一些新CPU支持的指令集在旧CPU上并不支持,因此在新CPU机器上启动的虚拟机迁移到使用旧CPU的机器上可能会失败。
相对来说冷迁移的实现要更简单一点,特别是Nova组件对接了后端云存储时,它的基本流程就是:
- 计算节点获取实例的磁盘、网络信息;
- 在新的计算节点上调用nova-compute服务启动一个实例
- 把云存储上的rbd文件映射到本地并启动虚拟机
- 绑定之前的网络端口到这个实例上让IP地址保持变。 虚拟机启动成功后即完成了冷迁移操作。
规格调整和冷迁移操作类似,首先根据规格调整操作过程中选择的新实例规格信息(通常新实例规格要比旧实例规格要大,例如CPU数量、内存数量、硬盘空间),然后在选择的计算节点上使用新的实例规格信息创建出新的实例,创建新实例的过程中还会调用后端云存储的API对RBD文件进行扩容,然后虚拟机启动以后调用cloud-init工具对磁盘进行扩容。
# 热迁移
热迁移指的是把一个正常工作的虚拟机迁移到另外的计算节点上,常见的场景有
- 监控组件发现这个实例所在物理机出现了硬件或者不可修复的软件故障需要停机修复
- 部分节点资源使用率比较低,需要调整计算节点资源负载以节省资源 为了避免虚拟机受到影响,需要提前把虚拟机迁移出去。
热迁移操作的主要难点是需要保证两个实例的数据一致性,因此在迁移过程中需要不断的把旧实例的内存数据拷贝到新实例上,因此需要判断底层的硬件性能(例如网卡带宽、PCI设备带宽)是否足够支撑热迁移,如果旧实例业务比较繁忙,特别是IO密集型操作,那么产生内存脏页数据的速度远大于迁移的速度,就会导致迁移失败。
同时热迁移最后一部分内存数据拷贝时,会把旧实例短暂挂起,完成最后一份内存脏数据的拷贝,此时旧实例会出现短暂的无法响应状态,因此如果实例上运行的业务属于IO敏感型的,那么可能会出现短暂的业务不可用情况。
# 重建和疏散
重建操作比较好理解,类似于重装操作系统,一般在需要清除虚拟机上的所有系统配置的时候,使用这个命令直接重建虚拟机,和手机恢复出厂设置操作一样。 重建的流程也比较简单:
- 使用镜像创建一个新的实例
- 实例启动过程中调用cloud-init工具注入实例元数据
- 把旧实例的网络端口绑定到新实例上
- 销毁旧实例 疏散这个操作从字面意思上理解,就是从当前节点撤离,一般在物理计算节点故障的时候使用,同时还要求虚拟机的系统盘和数据盘都使用网络存储才能够进行这个操作,这个时候nova会自动从正常工作的节点中选择一个新的节点来启动这个虚拟机。
# 虚拟机启动的完整流程
虚拟机启动流程开始部分和正常的物理机启动流程一样,唯一的区别在于启动完成后,cloud-init组件开始工作,这个组件会帮助完成一系列的初始化动作,例如:
- 获取虚拟机元数据
- 获取网络配置
- 获取用户注入信息
- 执行初始化脚本 等等操作。
# 虚拟机metadata获取流程
虚拟机路由->dhcp-agent -> haproxy -> metadata_proxy -> metadata_agent -> nova_metadata虚拟机启动过程中,dhcp-agent会向虚拟机中注入一条特殊路由,通常是:
169.254.169.254 192.168.116.150 255.255.255.255 UGH 1002 0 0 eth0
这个路由的目标地址通常是dhcp-agent的地址,如果dhcp-agent没有向虚拟机里注入特殊路由,则后面会提示no active metadata service.
虚拟机启动后,cloud-init工具会向下面这个地址请求主机的元数据:
http://169.254.169.254/1.0/meta-data
根据上面的路由规则,这个请求就会转发到dhcp-agent,而每个dhcp-agent都有一个自己独立的namespace,在控制节点上查看当前的网络名称空间如下所示:
ip netns
qdhcp-5c77a782-7534-45de-ba22-056ea7238d34 (id: 0)
2
qdhcp-开头的就是dhcp-agent的网络名称空间,我们查看这个名称空间的路由信息:
ip netns exec qdhcp-5c77a782-7534-45de-ba22-056ea7238d34 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.116.2 0.0.0.0 UG 0 0 0 ns-77c85b7e-d2
169.254.0.0 0.0.0.0 255.255.0.0 U 0 0 0 ns-77c85b7e-d2
192.168.116.0 0.0.0.0 255.255.255.0 U 0 0 0 ns-77c85b7e-d2
2
3
4
5
6
可以看到,请求路由到dhcp-agent后,是通过ns-77c85b7e-d2这个网卡出去的,然后我们看一下网卡 和IP信息:
ip netns exec qdhcp-5c77a782-7534-45de-ba22-056ea7238d34 ip ad
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen
1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ns-77c85b7e-d2@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state
UP group default qlen 1000
link/ether fa:16:3e:c0:c4:d7 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.116.150/24 brd 192.168.116.255 scope global ns-77c85b7e-d2
valid_lft forever preferred_lft forever
inet 169.254.169.254/16 brd 169.254.255.255 scope global ns-77c85b7e-d2
valid_lft forever preferred_lft forever
inet6 fe80::f816:3eff:fec0:c4d7/64 scope link
valid_lft forever preferred_lft forever
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
可以看到169.254.169.254就是附加到这个网卡上的IP地址,那么说明,请求就是在这里被处理的。下一步我们就要看,是哪个进程在监听80端口:
ip netns exec qdhcp-5c77a782-7534-45de-ba22-056ea7238d34 netstat -tlunp | grep 80
tcp 0 0 169.254.169.254:80 0.0.0.0:* LISTEN
3758/haproxy
tcp6 0 0 fe80::f816:3eff:fec0:53 :::* LISTEN
7822/dnsmasq
udp6 0 0 fe80::f816:3eff:fec0:53 :::*
7822/dnsmasq
2
3
4
5
6
7
8
可以看到,是一个haproxy在监听,对应进程是3758,查看这个进程信息:
ps aux | grep 3758
neutron 3758 0.0 0.0 47968 868 ? Ss 11:32 0:02 haproxy -f
/var/lib/neutron/ns-metadata-proxy/5c77a782-7534-45de-ba22-056ea7238d34.conf
2
3
4
是一个haproxy进程,我们看一下这个进程启动时使用的配置文件:
cat /var/lib/neutron/ns-metadata-proxy/5c77a782-7534-45de-ba22-056ea7238d34.conf
global
log /dev/log local0 info
log-tag haproxy-metadata-proxy-5c77a782-7534-45de-ba22-056ea7238d34
user neutron
group neutron
maxconn 1024
pidfile /var/lib/neutron/external/pids/5c77a782-7534-45de-ba22
056ea7238d34.pid.haproxy
daemon
defaults
log global
mode http
option httplog
option dontlognull
option http-server-close
option forwardfor
retries 3
timeout http-request 30s
timeout connect 30s
timeout client 32s
timeout server 32s
timeout http-keep-alive 30s
listen listener
bind 169.254.169.254:80
server metadata /var/lib/neutron/metadata_proxy
http-request del-header X-Neutron-Router-ID
http-request set-header X-Neutron-Network-ID 5c77a782-7534-45de-ba22-056ea7238d34
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
可以看到它把请求转发给了后端的metada服务器组,是一个metadata_proxy文件,同时还删除了网路路由ID的头部信息,添加了网络ID的头部信息。我们看下这个文件:
ll /var/lib/neutron/metadata_proxy
srw-r--r-- 1 neutron neutron 0 Nov 26 11:29 /var/lib/neutron/metadata_proxy
2
3
发现它是一个socket文件,socket文件一般用于同一台主机内部进程之间通信的,既然请求是从haproxy进来的,那是谁在监听这个socket文件呢?我们使用lsof命令查看是哪个进程在监听:
lsof /var/lib/neutron/metadata_proxy
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
/usr/bin/ 1084 neutron 5u unix 0xffff9a4231f9aa80 0t0 25501
/var/lib/neutron/metadata_proxy
/usr/bin/ 1938 neutron 5u unix 0xffff9a4231f9aa80 0t0 25501
/var/lib/neutron/metadata_proxy
/usr/bin/ 1939 neutron 5u unix 0xffff9a4231f9aa80 0t0 25501
/var/lib/neutron/metadata_proxy
2
3
4
5
6
7
8
9
发现有3个进程在监听,进程ID分别是1084,1938,1939,我们找一下这3个ID对应的进程:
ps aux | egrep '1938|1939|1084'
neutron 1084 1.6 1.2 396408 100504 ? Ss 11:29 3:03 /usr/bin/python2
/usr/bin/neutron-metadata-agent --config-file /usr/share/neutron/neutron-dist.conf -
config-file /etc/neutron/neutron.conf --config-file /etc/neutron/metadata_agent.ini -
config-dir /etc/neutron/conf.d/common --config-dir /etc/neutron/conf.d/neutron
metadata-agent --log-file /var/log/neutron/metadata-agent.log
neutron 1938 0.0 1.1 394444 93732 ? S 11:29 0:00 /usr/bin/python2
/usr/bin/neutron-metadata-agent --config-file /usr/share/neutron/neutron-dist.conf -
config-file /etc/neutron/neutron.conf --config-file /etc/neutron/metadata_agent.ini -
config-dir /etc/neutron/conf.d/common --config-dir /etc/neutron/conf.d/neutron
metadata-agent --log-file /var/log/neutron/metadata-agent.log
neutron 1939 0.0 1.1 394444 93732 ? S 11:29 0:00 /usr/bin/python2
/usr/bin/neutron-metadata-agent --config-file /usr/share/neutron/neutron-dist.conf -
config-file /etc/neutron/neutron.conf --config-file /etc/neutron/metadata_agent.ini -
config-dir /etc/neutron/conf.d/common --config-dir /etc/neutron/conf.d/neutron
metadata-agent --log-file /var/log/neutron/metadata-agent.log
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
发现3个进程都是neutron-metadata-agent进程,那么请求被neutron-metadata-agent进程获取后,根据它的配置文件:
nova_metadata_host = controller
metadata_proxy_shared_secret = INRV1Qqba62akutd
2
我们知道,它会根据配置里的地址信息和secret信息,把请求转发到了nova metadata元数据服务器,最后响应消息根据相反的流程返回给虚拟机。
# 实战项目:虚拟机救援
在日常的虚拟机维护工作中,经常会遇到虚拟机损坏导致虚拟机无法正常启动的故障,例如虚拟机使用人员误删了核心文件,物理节点故障导致虚拟机意外关机,从而导致的硬盘文件损坏等等。
在新版本的OpenStack中,则直接提供了救援的选项,如下所示,
点击救援实例按钮以后,他会根据你选择的镜像启动一个临时的服务器,并要求你为这个临时服务器设置一个密码,如下所示:
然后会把你故障虚拟机的系统盘挂载到这个临时服务器上,然后你就可以登录到这个临时服务器上对你的系统盘进行救援操作,例如修复系统核心文件,修改错误权限等等操作。比我们上面的手动操作更加简便。
在救援过程中需要注意的事项:
如果虚拟机使用LVM分区,不要使用相同的镜像启动临时服务器,会出现LVM vg卷组名冲突,导致无法正常挂载故障虚拟机磁盘。可以使用手动分区的镜像来启动。
# 手动救援操作流程
在旧版本的OpenStack中,针对实例没有提供救援功能,需要自己来手动来操作,或者是虚拟机被意外删除核心文件,导致虚拟机完全无法启动,需要自己手动来处理,就像我们课程上演示的那样, 直接执行了rm -rf /*操作,导致系统无法启动。
nova对接云存储修复
这种是最简单的,因为对应的磁盘文件就是后端云存储中的一个rbd文件,那么基本修复流程就是:
- 从Ceph云存储中vms存储池中导出这个RBD文件,通常是一个磁盘同等大小的文件;
- 在OpenStack上创建一个同等大小的数据卷,此时会在云存储的volumes池里创建一个同等大小的空白RBD文件;
- 把第一步中导出的RBD文件导入到volumes池中的数据卷RBD文件,
- 把这个数据卷挂载到用来修复的临时实例中作为数据卷(和上面自动修复一样,不要使用相同分区格式的镜像);
- 挂载好以后使用chroot命令切换到数据卷环境中进行修复工具,例如复制误删除的库文件,重新安装缺少的包,或者拷贝重要数据;
- 完成修复工作以后,在Ceph云存储中导出该数据卷RBD文件,重新导入到vms池中,覆盖故障的虚拟机RBD文件
- 覆盖完成后,重新启动故障虚拟机进行验证。